How a Container Runtime is using CNI
The last couple of years I have been working with containers in low level. I learned how they work under the hood and I got familiar with container standards like OCI (Open Container Initiative) and CNI (Container Network Interface). When it comes to the runtime spec, there are quite many resources which explain in detail the runtime standard. On the other hand, there are not many resources about CNI, and it has not been clear to me how the runtime engine is using the CNI standard, as well as how difficult is to write a network CNI compatible plugin.
Introduction to CNI
CNI stands for Container Networking Interface, and it targets to standardize the interface between the container runtime engine and the network implementation. It is a minimal standard way to connect a container to a network.
There are three things that CNI project offers
- The CNI Specification
- A golang library which provides an implementation of the CNI specification
- Plugins : reference implementation for a variety of use-cases
How it works can be summarized in the following image
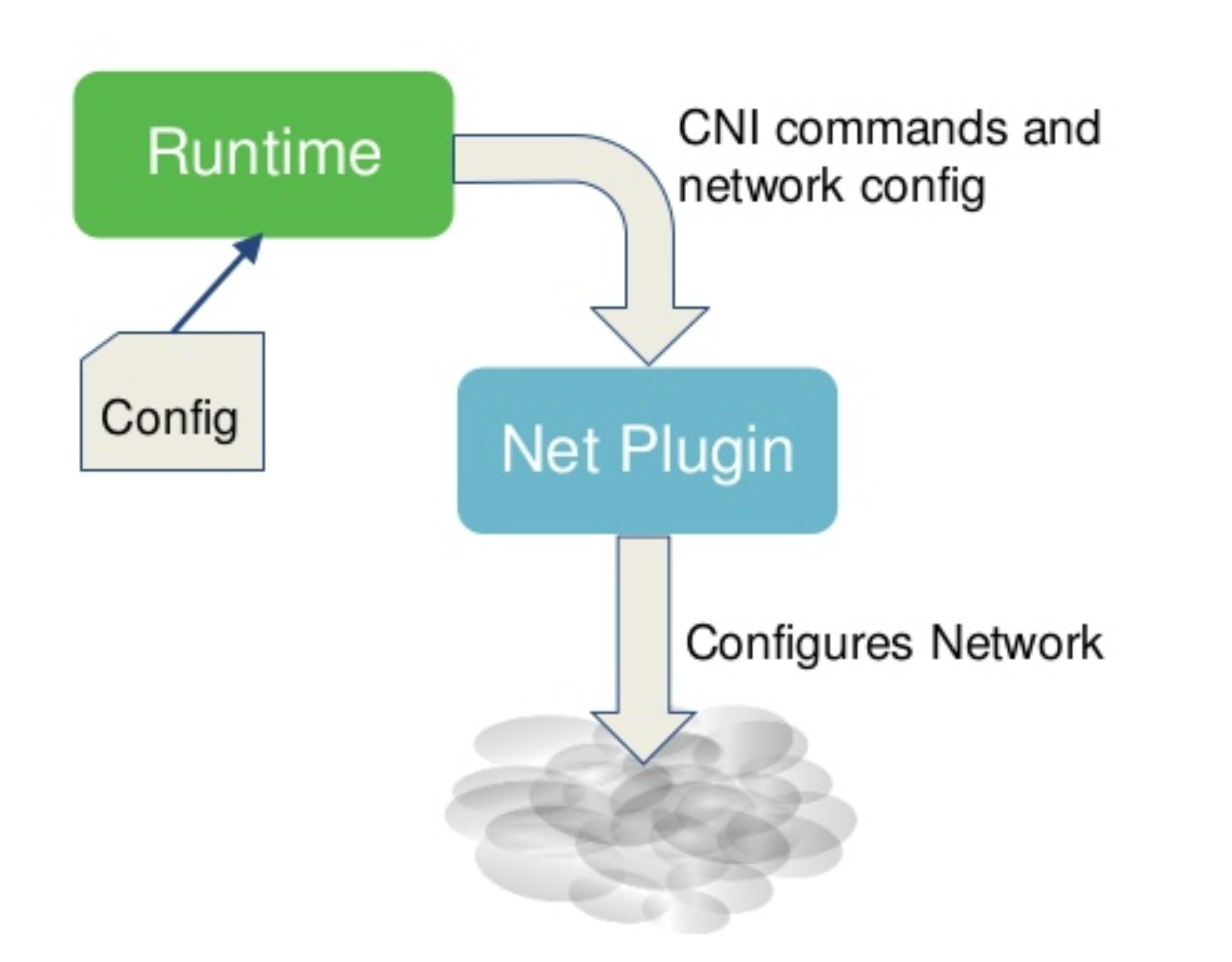
When discussing about CNI, there are some information that I find nice to keep in mind:
- A plugin that implements the CNI standard is binary, not a daemon. It should always have at least CAP_NET_ADMIN capability when runs.
- Network definitions or network configuration are stored as json files. These
json files are streamed to the plugin through
stdin. - Any information that is only known when the container is
to be created (runtime variable) should be passed to the plugin via
environmental variables. Nevertheless, in the latest CNI it is also possible
to send certain runtime config via
jsononstdin, especially for some extension & optional features. More info here. - The binary does not suppose to have any other input configuration outside the above two.
- The CNI plugin is responsible for wiring up the container, and is expected to hide the network complexity.
- For a CNI plugin a container is the same thing as Linux network namespace.
its an advanced use case, but its also an interesting point because it means that the runtime essentially modifies the config JSON after the operators provides it, but before the plugin sees it.
Container Runtime
In a OCI/CNI compatible version, the Container Runtime [Engine] is a daemon process that sits between the container scheduler and the actual implementation of the binaries that create a container. This daemon does not necessarily need to run as root user. It listens for requests from the scheduler. It does not touch the kernel, as it uses external binaries through the container standards to actually create or delete a container.
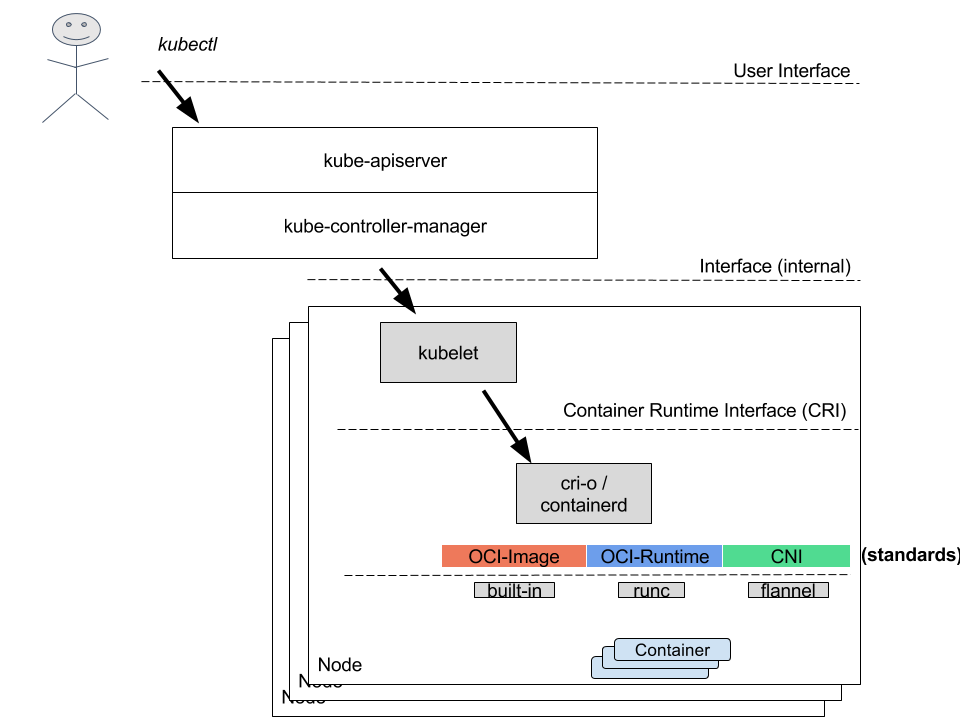
For example in kubernetes case, the Container Runtime can be cri-o, (or cri-containerd), it listens for requests from the kubelet, the agent from the scheduler located in each node through the CRI interface. Kubelet is instructing the Container Runtime to spin up a container, and the runtime is executing by calling in a standard way the runc (binary that implements the OCI-runtime specs) and flannel (binary that implements the CNI CNI). The above process is summarized in the following image.
Container Runtime needs to do the following in order to create a container:
- Creates the
rootfsfilesystem. - Creates the container (set of process that run isolated in namespaces and limited by cgroups).
- Connects the container to a network.
- Starts the user process (entrypoint).
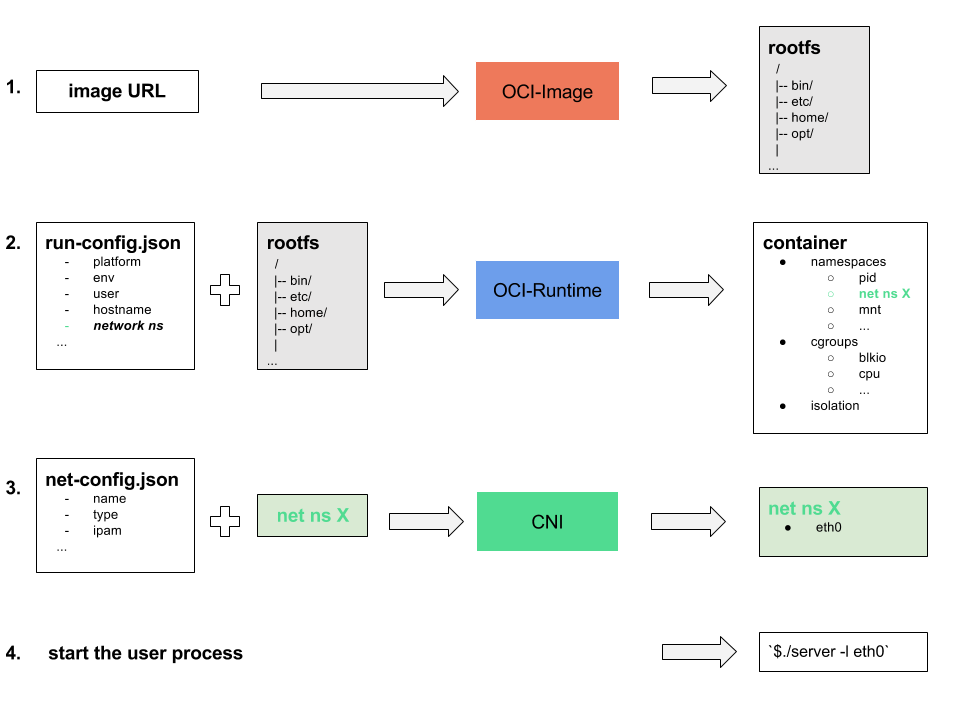
As far as the network part is concerned, important is that the Container
Runtime asks from the OCI-Runtime binary to place the container process into
a new network namespace (net ns X). The Container Runtime in the next step
will call the CNI plugin using the new namespace as runtime ENV variable.
The CNI plugin should have all the info in order to do the network magic.
How Container Rutime Uses CNI
We will give an example how a runtime uses CNI to connect a container to a bridge using the bridge plugin. We will “emulate” the actions of the runtime using simple bash commands.
Provision Phase
Before a runtime can spin up a container it needs some server provisioning.
Which tool is being used (e.g bosh, ansible, manual scripts) is irrelevant. It
only needs to make sure that the required binaries are in place. In our simple
case we need the OCI-runtime binary (runc) and the CNI plugins binaries
(bridge, host-local).
We can either download the pre-built binaries from the repos or we can build the binaries from source
# as user
go get github.com/opencontainers/runc
go get github.com/containernetworking/plugins
cd $GOPATH/src/github.com/containernetworking/plugins
./build.sh
sudo mkdir -p /opt/cni/{bin,netconfs}
sudo cp bin/* /opt/cni/bin/
which /opt/cni/bin/{bridge,host-local} runc
During the provision step, we create the bridge to where containers will be connected.
# as root
ip link add name br0 type bridge
ip addr add 10.10.10.1/24 dev br0
ip link set dev br0 up
This step might not be required because the bridge plugin can create the
bridge, but in principle setting up the network medium is not a task from
the CNI plugin.
Finally, we should add the network configuration somewhere on the filesystem.
# as root
export NETCONFPATH=/opt/cni/netconfs
cat > $NETCONFPATH/10-mynet.conf <<EOF
{
"cniVersion": "0.2.0",
"name": "mynet",
"type": "bridge",
"bridge": "br0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.10.10.0/24",
"routes": [
{ "dst": "0.0.0.0/0" }
],
"dataDir": "/run/ipam-state"
},
"dns": {
"nameservers": [ "8.8.8.8" ]
}
}
EOF
Runtime Phase
The container orchestrator will eventually instruct the container runtime to spin up a container.
Runtime will do the following simplified steps [as shown in the figure above]
# Step 1: creates the rootfs directory
mkdir bundle && cd bundle/
mkdir -p rootfs && docker export $(docker create busybox) | tar -C rootfs -xvf -
# Step 2:
# a. creates the OCI runtime config
runc spec --rootless
# b. modifies the OCI runtime config accordingly
# asks for a new network namespace, other changes e.g. tty
# cat config.json |grep -A20 namespace
# "namespaces": [
# {
# "type": "pid"
# },
# {
# "type": "ipc"
# },
# {
# "type": "uts"
# },
# {
# "type": "mount"
# },
# {
# "type": "user"
# },
# {
# "type": "network" <--adds network namespace
# }
# ],
# "maskedPaths": [
#
# c. creates the container
runc create cake
# $ runc list
# ID PID STATUS BUNDLE CREATED OWNER
# cake 13076 created /home/vagrant/bundle 2018-01-22T13:09:40.326479248Z vagrant
runc exec -t -c "CAP_NET_RAW" cake sh # To enter the container
The Container Runtime needs to get back the newly created network namespace.
In the runc case, this can be done through the state.json file.
# as root
ns=$(cat /var/run/user/1000/runc/cake/state.json | jq '.namespace_paths.NEWNET' -r)
mkdir -p /var/run/netns
ln -sf $ns /var/run/netns/cake
ip netns
# cat /var/run/user/1000/runc/cake/state.json | jq '.namespace_paths'
# {
# "NEWIPC": "/proc/13076/ns/ipc",
# "NEWNET": "/proc/13076/ns/net",
# "NEWNS": "/proc/13076/ns/mnt",
# "NEWPID": "/proc/13076/ns/pid",
# "NEWUSER": "/proc/13076/ns/user",
# "NEWUTS": "/proc/13076/ns/uts"
# }
# $ ps -aux |grep 13076
# vagrant 13076 0.0 0.3 58016 6848 ? Ssl 13:09 0:00 runc init
# # the `runc init` is the process that starts when `runc create` command is
# # executed and which keeps the namespaces alive
#
It will then set bash enviroment variables (CNI_*) which contain runtime
information like the network namespace.
export NETCONFPATH=/opt/cni/netconfs
export CNI_PATH=/opt/cni/bin/
export CNI_CONTAINERID=cake
export CNI_NETNS=/var/run/netns/cake
export CNI_IFNAME=eth0
export CNI_COMMAND=ADD
Finally it will call the CNI binary providing in the stdin the configuration
and the above variables. Runtime will get back the results in json format.
cat $NETCONFPATH/10-mynet.conf | $CNI_PATH/bridge
# $cat $NETCONFPATH/10-mynet.conf | $CNI_PATH/bridge
# {
# "cniVersion": "0.2.0",
# "ip4": {
# "ip": "10.10.10.2/24",
# "gateway": "10.10.10.1",
# "routes": [
# {
# "dst": "0.0.0.0/0",
# "gw": "10.10.10.1"
# }
# ]
# },
# "dns": {
# "nameservers": [
# "8.8.8.8"
# ]
# }
# }
#
We can observe by running ip commands inside the container network space that
the interface has been properly set up.
# $ ip netns exec cake ip a s eth0
# 3: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
# link/ether d6:d6:48:92:b3:25 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# inet 10.10.10.2/24 scope global eth0
# valid_lft forever preferred_lft forever
# inet6 fe80::d4d6:48ff:fe92:b325/64 scope link
# valid_lft forever preferred_lft forever
# $ ip netns exec cake ip route
# default via 10.10.10.1 dev eth0
# 10.10.10.0/24 dev eth0 proto kernel scope link src 10.10.10.2
#
From the result output, one thing that is a bit confusing is the DNS result
entry. CNI plugin do not actually apply the DNS entry (aka. write the
/etc/resolv.conf). The plugins simply return the value, and the Container
Runtime is expected to apply the DNS server.
The delete case works simply by changing the action CNI_COMMAND
export CNI_COMMAND=DEL
cat $NETCONFPATH/10-mynet.conf | $CNI_PATH/bridge
# no output expected when success
Multi-Interface Case
Often there is a need for connecting a container to more than one networks.
This can happen through multiple network configurations in $NETCONFPATH
The expected behavior of a runtime can be demonstrated in the following
bash snippet
export CNI_COMMAND=ADD
for conf in $NETCONFPATH/*.conf; do
echo "${CNI_COMMAND}ing $conf"
export CNI_IFNAME=$(cat $conf | jq -r '.name')
plugin=$(cat $conf |jq -r '.type')
echo "cat $conf | $CNI_PATH/$plugin"
res=$(cat $conf | $CNI_PATH/$plugin)
echo $res | jq -r .
done
It basically loops over each network configuration and adds a normal.
Take Away Notes
CNI is about all the network-related actions that take place during the creation or the deletion of a container, it is not about realtime changes (e.g. policy enforcement). CNI will create all the rules to reassure a connection from/to a container, but it is not responsible to set up the network medium, e.g. bridge creation or distribute routes to connect containers located in different hosts. CNI targets to hide the network complexity in order to make the runtime code-base cleaner and in the same time to enable third party providers to create their own plugins and integrate them easily to all container orchestrators that are using a CNI compatible runtime.
Links
Some nice readings on the topic